| Figyelem, a senki ne próbálja ki otthon a következőkben látottakat. Az itt bemutatott kódrészleteket mentálisan (nem) felkészült varázslók, sok órán keresztül készítették. Házilag készített programokban kerülendő minden, ami ezen az oldalon található. |
Mindenki látott már olyat, esetleg járt már maga is úgy, hogy a program tervezése közben a különféle mérnöktudományok alkalmazói beépítik magukat egy olyan sarokba, ahonnan már nem tudnak épeszű eszközökkel kimászni. Ilyenkor keletkeznek olyan megoldások, amiket a fehér járolapkra nem lépő kisgyerekek produkálnak, olyan helyen, ahol a fekete járólap véget ér: hosszú távon semmi képpen sem működőképes tákolmányok, mint a legközelebbi felnőttel arrébrakatni magukat. De hát ha belegondolunk, a Win32 subsystemtől, X11-en keresztül, <oprendszer> bluetooth implementációjáig, mind a mai napig használt programok, amikre ha újdonságok lennének mindenki azt mondhatná, hogy ezek hosszú távon egyáltalán nem működtethető tákolmányok.
Ez a cikk egy ilyen szituációt ír le.
A probléma
Mielőtt nekilátnánk a különféle trükkök bemutatásához, kerüljön ismertetésre a probléma.
Az egész szituáció a Prog2 tárgy nagy házi feladatának elkészítése közben történt. Az ajánlott feladatok közül (Prog2 HF ötletek) a "Konfiguráció beolvasó" című feladatot választottam, mert relatíve egyszerűnek tűnt, illetve szinte mindig könyvtárakat írok, így ez elég jól kezelhető volt. Emellett a feladat megengedte a szabányos tárolókat és algoritmusokat, amiket nem sok kedvem lett volna újraimplementálni.
Az egy “nehézsége” a feladatnak, hogy adott T típusra a beolvasott és sztringként tárolt adatokat T objektummá kell konvertálni.
Bár a feladat specifikálta, hogy elegendő, olyan T típusokra működni, amelyekre értelmezett a operator>>(std::istream&, T&) függvény, de nyilván ettől eltekintünk, mert tudjuk, hogy az iostream interface amúgy is lassú, így csak olyan esetekben használatos, ahol a nagyon könnyű bővíthetőség fontos.
Itt például az lett volna, de hát ugye rendesen végiggondolni a követelményeket a gyengéknek való, befutni a sarkoba, hogy utána körbeépítse magát az ember az igazi csanád lépés.
A (feltételezett) implementáció
Majdnem minden, ami a következőkben található, lecserélhető három függvénnyel.
Az tárolt objektumot T típusként lekérdező tagfüggvény (config::get_as<T>(std::string_view key)), és
ként konverziós függvény, egy, ami működik, egy pedig, ami a jobb hibaüzeneteket szolgálja.
Ez utóbbi kettő lecserélhető egy egyszerűbb függvényre, ha úgy gondoljuk, hogy a compiler hibaüzenetei elegendőek
a be-krokodil operátort nem támogató fordítási hibák orvoslására.
Szükség van még egy egyszerű segédosztályra, de ez tényleg olyan egyszerű, mint a faék:
template<class>
struct fail {
constexpr const static auto value = false;
};Ez az osztály látja el azt a feladatot, hogy a fordító ne legyen túl okos.
Mivel a static_assert opererátort fogjuk használni a hibaüzenet generálására, így kell egy olyan osztály,
ami indirekciót biztosít a static_assert és a false érték között, hiszen static_assert(false); minden esetben
azonnali fordítási hiba.
Így már egyszerűen implementálható a két parseoló függvény, ebből pedig a get_as<T>.
A sikertelen parseolás egyszerűbb:
template<class T>
struct obj_parser {
constexpr static T parse_obj(std::string_view) noexcept {
static_assert(fail<T>::value,
"Given type T, used in config::get_as<T> cannot be parsed from a string. "
"Implement the operator>>(std::istream&, T&) function.");
}
};A sikeresnél két megoldás létezik.
C++20-as szabvánnyal megkaptuk a concept kulcsszót, ami a template metaprogramozást jelentősen könnyíti, így a következő módon pár sorból implementálható a függvény.
A másik implementációt most nem tárgyaljuk, mert nem ez a fő célja ennek a cikknek, csupán összehasonlítás céljából kerül bemutatásra az “elvárt” megoldás.
Emellett jelentősen komplikáltabb.
template<class T>
concept in_readable = requires (T obj) {
{ std::istringstream{} >> obj } -> std::common_reference_with<std::istream&>;
};
template<in_readable T>
struct obj_parser<T> {
static T parse_obj(std::string_view data) { (1)
std::istringstream ss(std::string(data.data(), data.size()));
T obj;
ss >> obj;
return obj;
}
};| 1 | A noexcept kifejezés jelentősen elkomplikálná a példát így lekerült a példáról, főleg, hogy a szabvány szerint az std::basic_istringstream<…> konstruktora nem noexcept, így ennek megfelelő implementációk esetén, nem lehetne a függvény ténylegesen noexcept soha. |
Ezzel már tényleg triviális a get_as<T> függvény implementálása.
template<class T>
T get_as(std::string_view key) {
const auto str_val = get(key); (1)
return impl::obj_parser<T>::parse_obj(str_val);
}| 1 | get(std::string_view) itt a sztring értékként visszatérő konfigurációt kereső tagfüggvény. |
A tényleges probléma
Az előzőekben bemutatottak szerint, a feladat nem lett volna egetrengetően nehéz. Mégis létezik ez a cikk, tehát valami történt, különben szóra se lenne érdemes az egész helyzet.
Mint mindenki, aki csinált Progn (\$n in NN\$) nagy názi feladatot tudja, hogy, amikor a specifikációt írja az ember, sikerül szinte biztosan valami olyat beleírni, amivel utána szív az implementáláskor.
Ez ebben az esetben a cachelés.
Gondolta bodand, végtelen IQ-jával, hogy, mi lenne akkor, ha minden T-re lekérdezéskor a konstruált T objektumot elmentené a könyvtár, így nem lenne szükség újrakonstruálásukra.
Utólag, igazán jó ötlet, meg kell mondjam…
Ebből következően el kellett mentenem ismeretlen T típusú objektumokat, úgy, hogy egy tárhelyen (egy config objektum cache mezőjében) az érték változhat, mivel a cache mindig az utolsó lekérdezett típusú objektumot tárolja.
És itt kezdődi a szaga a sebességért.
A klasszikus visitor pattern
Az alap felállás, hogy létezik egy cache ősosztály, ami minden megfelelő típusnak tárolja az adatait, a számára megfelelő helyen, a gyerekosztályon belül.
Például, az alábbi részlet az int értékeket tárolja.
struct int_cache : visitable_cache<int_cache> {
int_cache(int&& data) noexcept : _data(std::move(data)) { }
const int*
get_value_ptr() const { return &_data; }
private:
int _data;
};|
A |
Ez így nagyon szép, és nagyon jó, viszont így két problémával állunk szemben.
Nem tudjuk, hogy az adott típus, amit a cache tárol megfelelő-e, a most lekérdezett T típusnak,
illetve ha tudjuk is, C++-ben nem létezik minden típus által osztott közös fő-ős (mint, pl. Java Object),
így nincs megfelelő interfaceünk a különböző cache osztályok implementálására.
A második problémára létezik egy már régóta ismert megoldás: amikor különböző osztályokkal kell dolgozni, amiket tudni kell feldolgozni egy helyen, de annyira különböznek, hogy nem érdemes külön közös ősbe felemelni a tagfüggvényeket, akkor jönnek be a látogatók (Visitor). Ezek még a GoF könyvben definiált visitor-pattern-nek az implementációja, ami egy közös ős létrehozását igénybe veszi, viszont nem kell ennek mást csinálnia, csak egy látogató fogadó függvényt biztosítania.
Lássunk egy gyors példát.
struct my_type; (1)
struct your_type; (1)
struct visitor_base {
void visit(my_type& my) { /*...*/; } (2)
void visit(your_type& your) { /*...*/; } (2)
};
struct base {
virtual void accept(visitor_base&) const = 0;
};
struct my_type : base {
void accept(visitor_base& vtor) { vtor.visit(*this); } (3)
/*...*/;
};
struct your_type : base {
void accept(visitor_base& vtor) { vtor.visit(*this); } (3)
/*...*/;
};| 1 | A visitor pattern implementálásakor meg kell kötnünk az osztályokat, amikre érvényes a visitor.
Ez szükséges, hiszen a visit tagfüggvény overloadjait előre létre kell hozni. |
| 2 | Az aktuális implementációt, olyan nyelvekben, mint a C++, szükség van külön a forrás (nem fejléc) fájlban való implementálásra, és a teljes típus #includálására. Ezt nem lehet a fejlécben megtenni, különben körkörös #include láncot kapunk. |
| 3 | Az implementálás minden leszármazott osztálynál pont ugyan így néz ki.
A fent látott visitable_cache ezt a copy-pastelt kódrészletet szűnteti meg. |
Az előbbi a klasszikus implementációja a visitor patternnek.
Ez lehetővé teszi számunkra, hogy minden cache osztály egy saját get_*ptr függvényt biztosítson, anélkül, hogy egy közös ősbe kellett volna integrálni az összes get*_ptr függvényt, és minden nem megfelelő osztálból nullptr-t visszaadni a sok fölölsleges függvényből.
Mert a void* minden létező típusinformációt eldob, így semmi hasznosat nem lehet már utána megtudni róla.
Emiatt fontos, hogy ha szükség is van void* használatára, azt minél jobban leszükített környezetben történyjen.
Jelenleg is van szükség rá, mellesleg, viszont mélyen elrejtve a dinamikus visitor implementációjában.
Így nincs a felhasználó szemében, aki így nem tud vele rossz dolgokat csinálni; hiszen saját típusra a cache-t neki kell megírnia, így a void* interface a felhasználóra lenne bízva.
Ez minden esetben rossz, mert ugye a felhasználó nem tudja, mit csinál.
Soha.
(Mi sem, de az nem számít.)
Van azonban egy probléma a klasszikus implementációval. Mivel előre kell ismerni az összes olyan osztályt, amit látogatunk, így az osztályok halmaza egy zárt halmazt alkot: nem lehetséges új osztály hozzáadása minden létező visitor módosítása nélkül, hiszen az őslátogatót kell módosítani.
A mi szitációnkban azonban a látogatandó osztályok halmaza nyitott, hiszen a felhasználónak csinálnia kell új osztályokat, ha nem csak a beépített típusokat szeretné elcachelni.
A dinamikus visitor naívan
Itt jön be dinamikus visitor: úgy kell implementálni egy visitor mintázatot, hogy ne kelljen lezárni az osztályok halmazát.
Gondol, gondol, gondol.
A kézenfekvő megoldás, amit elsőre megötlöttem, hogy csak szimplán dynamic_cast-al egyszerűen lehet implementálni egy ilyen problémát, hiszen egy hierarchiában kell átcastolni máshová a dolgokat.
Pont, amire dynamic_cast való.
Gyorsan össze is lett állítva az első implementáció.
Az előzőekben látott visitor_base-t ki kellett cserélni egy olyan típusra, ami nem csinál semmit, pusztán egy visitor visitorságát jelzi.
struct visitor_base {
virtual ~visitor_base() = default;
};Ebből lehetett továbbörökölni a megfelelő osztályokat látogatni képes visitor_impl osztály sablont.
Mivel így minden típusra létezik külön visitor_impl, így nem kell előre ismerni az összes típust, csak akkor, amikor az osztály sablont instanciáljuk.
Bár ez nem tűnik sokkal jobb helyzetnek, pedig az.
A visitor, ami szeretne egy osztállyal csinálni valamit, annak mindenképpen ismernie kell egy adott osztályt, így nem adunk hozzá plusz ismeretségi feltételt a kódunkba, csak olyanokat használunk, amelyek már léteznek.
Ezzel tehát, egy adott osztály meglátogató visitor implementáló osztály sablon:
template<class T>
struct visitor_impl : virtual visitor_base {
virtual void do_visit(T&) = 0;
protected:
~visitor_impl() override = default;
};Innen pedig már egy egyszerű lépés egy olyan visitort csinálni, ami adott T… típusokat képes meglátogatni.
template<class... Ts>
struct visitor : visitor_impl<Ts>... {
~visitor() override = default;
};Ez eddig szép és jó, de nem oldotta meg teljesen a problémánkat.
A visitor objektumok már tudnak örökölni visitor<T, U, V, W> osztályból, így tempalte metaprogrammingal állíthatóak, hogy mely osztályokat tudják meglátogatni.
A probléma még a fogadói oldalon áll fenn.
Az accept függvény, ami eddig pusztán *this-t adott a paramétere egy tagfüggvényének nem működhet tovább, hiszen frakturáltuk a visitorok hiearchia fáját.
Míg eddig minden visitor_base-en keresztül történt, már nem tudjuk ezt megoldani, hiszen a do_visit függvény már, típushelyesen, a különböző visitor_impl osztályokban található.
Erre megoldás a dynamic_cast.
Minden visitort megpróbálunk lecastolni a megfelelő visitor_impl<T> osztállyá.
Akármennyire barbár megoldás ez, nem mutatokozott jobb ötlet az egész nyitott osztályhalmazt támogató látogatókra.
Úgyhogy oda nem nézve, sarokba szorulva, a következő kód született:
template<class Base, class T>
struct visitable_as : Base {
using Base::Base;
void accept(visitor_base& dyn_vtor) override {
if (auto vtor = dynamic_cast<visitor_impl<T>*>(&dyn_vtor)) {
auto self = static_cast<T*>(this);
assert(self);
vtor->do_visit(self);
}
}
~visitable_as() override = default;
};Ez a kód tette lehetővé, hogy egy látogatható osztály hierarchia tagjai “belépjenek” a látogathatóságba.
Az öröklési láncba beinjektálva ezt az osztályt, a hierarchia alapjában adott accept virtuális függvényt “el tudtuk lopni” a leszármazott osztálytól, és úgy implementálni, hogy, ha a látogató képes rá, akkor a megfelelő osztályra típushelyesen meghívódjon a do_visit tagfüggvény.
Ez az osztály igazából nem feltétlen szükséges, hiszen teljes mértékben implementálható minden osztályban a logika, viszont így a felhasználó hierarchiának nem felelőssége a tőleg független látogató rendszer kezelése, csak el kell szenvednie a látogatást.
Ezen felindulásból a tényleges kódban létezik egy visitable_hierarchy osztály is, amiből az ősosztály örökölhet, így neki sem kell még az accept függvénnyel foglalkoznia.
Itt ez helyspórolás célokból kivágásra került.
struct base {
explicit base(int a)
: _a(a) { }
virtual void accept(visitor_base& vis) = 0;
virtual ~base() = default;
private:
int _a;
};
struct der1 : visitable_as<base, der1> {
der1()
: visitable_as<base, der1>(1) { }
};
struct der2 : visitable_as<base, der2> {
der2()
: visitable_as<base, der2>(2) { }
};
struct der3 : visitable_as<base, der3> {
der3()
: visitable_as<base, der3>(3) { }
};| A következő implementációk során a hierarchia felé felállított interface nem változik, az előző kód, tehát minden esetben érvényes. |
A próba program lefordult.
Nagy boldogság következett.
Viszont volt egy zavaró dolog a történetben; a kód dynamic_cast lecastoló képességeire hagyatkozott, és bár azon állásponton vagyok, hogy dynamic_cast minden esetben egy design problémát takar, nem volt hirtelen jobb ötlet, kikerülni.
Az igazi motivációt dynamic_cast megkerülésére valami más adta: az Intel VTune Profiler.
Sebesség
Fontos tudni, hogy dynamic_cast nem csak lefele castolást tesz lehetőve, hanem gyakorlatilag bárhová az osztályhierarchiában.
Ez viszont irgalmatlan lassúvá teszi szegényt.
Így, ha “csak” lecastolni kell, jelentős sebességbeli problémákat tud fog okozni.
Ezt tudva, csak mértékét nem ismerve ellenőrzés céljából VTune-ra lett bízva, hogy vizsgálja meg a kódot.
A következő egy kép egy tesztprogram hotspotjairól, ami sokszor elvégzett egy 3+1 tagú hierarchiában egy látogatást.
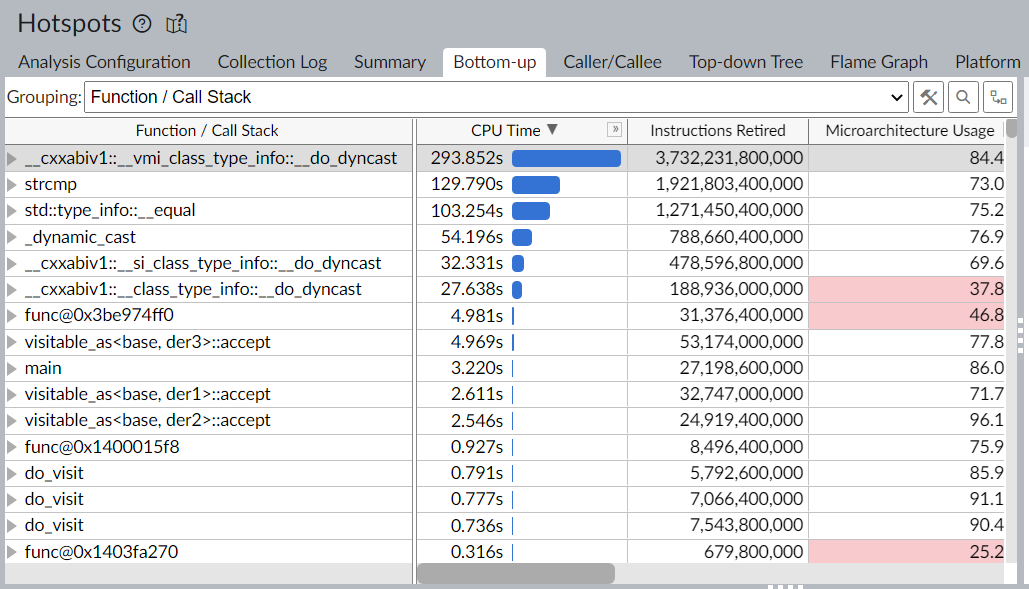
No lám, no lám.
Majdnem az egész runtimeot a dynamic_cast futásideje határozza meg, minden más gyakorlatilag elhanyagolható futásidővel rendelkezik.
Ez elég meggyőző szerintem mindenki számára, hogy ebben a pillanatban minden dynamic_cast-ot használó kódot refaktoráljon, hogy véletlenül se hívódjon meg dynamic_cast.
Dinamikus visitor, dynamic_cast nélkül
Akkor vissza a tervezőasztalhoz.
Ha nem dynamic_cast, akkor mi legyen, hogy a dinamikusságot meg tudjuk tartani.
Ideálisan semmilyen *_cast-ra nincs szükség, minden pont úgy típusos, hogy nem kell erőszakosan konvertálgatni innen-oda 's vissza.
Viszont ez a probléma már úgy is olyan tákolt szituációt állított elő nekünk, mint a sarokban már egy lábon álló informatikusoknak, hogy a utópikis castolásmentes világképet nyugodtan eldobhatjuk.
Marad hát a static_cast, ami, hát, hogy is mondjam, statikus.
Egyszerűen csak a fordítási időben játszik szerepet, hogy a fordító boldog legyen olyan dolgokkal, amik amúgy is a futásidőben meg tudnának történni.
Első lépés, hogy valamilyen futásidejű típusinformációra van szükség.
Szerencsére (vagy nem, mindenki döntse el magának) a szabvány biztosítja számunkra a <typeinfo> fejlécet.
Ezzel használhatóvá válik a typeid operátor, amivel egy adott típust lehetséges (implementation defined formátumú) futásidőbeli információvá változtatni.
Ezzel el tudjuk csúsztatni az implementációt, hogy megcsináljuk azt a részét a dynamic_cast-nak, amire szükségünk van.
Ehhez visitor_base visszakapja a visit függvényét, ámbár most már függvény sablon formájában és egyszerűen csak delegálja a munkát egy másik tagfüggvénynek.
Utóbbi azonban típusmentes, és virtuális, lehetővée teszi számunkra, hogy normál virtuális függvényként kezeljük és a megfelelő utódban fölülírjuk.
struct visitor_base {
template<class T>
void visit(T* visited) {
visit_imp(static_cast<void*>(visited), typeid(T));
}
virtual ~visitor_base() = default;
protected:
virtual void
visit_imp(void*, const std::type_info&) = 0;
};A void* paraméter C++ kódban általában nagyon gyanús, de mindenképpen jobb, mint dynamic_cast.
Itt azonban felhasználjuk, hogy az objektumot a futásidőben szétválasszuk: void* a memóriabeli helyéből, és std::type_info a típusinformáicóból.
Ebből a két adatból képesek leszünk újrakonstruálni az objektumra mutató pointert, amikor szükség lesz rá.
A másik lépés már csak annyi, hogy a visit_imp függvényt implementáljuk.
Ezt a visitor osztály sablonban fogjuk megtenni, békénhagyva a visitor_impl osztály sablont.
Elsőként, definiálunk egy olyan tagfüggvényt, ami megnézi egy darab típusra, hogy azonos-e a jelenleg ellenőrzött T típus a valdi objektum típusával, és ha igen, meglátogatja a megfelelő visitor_impl<T> használatával.
A függvény egyszerűen csak összehasonlítja a megadott T típus std::type_info-ját a paraméterként kapott std::type_info-val, ami ha egyezik T-vel azonos típusú objektum található a void* mögött.
Ha talált egy megfelelő típust, igazat, különben hamisat ad vissza.
Ez a tulajdonsága még hasznos lesz.
template<class... Ts>
template<class T>
bool visitor<Ts...>::visit_one_t(void* typeless_visited, const std::type_info& tid) {
if (typeid(T) != tid) [[likely]] return false; (1)
static_cast<visitor_impl<T>*>(this)->do_visit( (2)
static_cast<T*>(typeless_visited)); (3)
return true;
}| 1 | A |
| 2 | Itt már, az előző megoldással szemben felfele castolunk.
Ez jeletősen jobb, hiszen felfele mindig biztonságos castolni[1], és fordítási ídőben meg tud történni, hiszen igazából nem történik semmi.
És mivel itt már tudjuk, hogy melyik visitor_impl anyaosztállyá kell átváltoznunk, egyszerűen felkonvertáljuk magunkat. |
| 3 | Ez a static_cast csak szimplán a void*-ból visszanyeri azt a típusos mutatót, amivel eredetileg is rendelkeztünk. |
A visit_imp függvényt pedig ezzel a függvénnyel triviális implementálni.
Egyszerűen minden támogatott típusra (Ts…) meg kell nézni, hogy azonos-e a jelenleg vizitálandó típussal, és ha igen meg kell látogatni.
Mivel Ts… egy parameter pack, így egy fold-expressionnel (nem szeretném lefordítani) egyszerűen össze lehet egymás után láncolni az összes ellenőrzést, minden fordítási idő generáló sablonrekurzió és egyéb trükkökk nélkül:
template<class... Ts>
void
visitor<Ts...>::visit_imp(void* typeless_visited, const std::type_info& tid) final {
(visit_one_t<Ts>(typeless_visited, tid) || ...);
}A rövidzár tulajdonságára hagyatkozva a || operatáronak, ez addig fogja probálgatni a típusokat, amíg talál megfelelőt, vagy el nem fogynak.
Ezzel gyakorlatilag implementáltuk dynamic_cast azon részét, amire szükségünk van, minden más fölösleges dolog nélkül.
Ráadásul, mivel van több információnk, mint a teljesen általános dynamic_cast-nak, így nem szükséges még ciklusokat se beépítenünk,
amelyekből több is van a dynamic_cast belsejében (leglábbis VTune azt mondja, hogy ott vannak ciklusok).
Emellett, még a visitable_as kódja is módosul, a jó irányba, egyszerűsödik.
Mivel eddig a legfelső pointert kaptuk a hierarchiában és a megfelelő típust meg kellett keresni, hogy abba lecastoljunk, mivel az általános típus semmit nem tudott, csak jelezte, hogy a hierarchia egy tagja valami.
Most már képes a vizitálás kezdeményezésére, hiszen megkapta a visit tagfüggvénysablont, ami pedig a megfelelő virtális függvényt fogja meghívni.
Ez megegyezik az általános—és helyes—használatával az osztályhierarchiáknak, így jelentősen jobb, és gyorsabb is a kód.
Mindezzel, az accept kódja:
tempalte<class Base, class T>
void visitable_as<Base, T>::accept(visitor_base& vtor) override {
auto self = static_cast<T*>(this);
assert(self);
vtor.visit(self);
}| Itt van még egy trükk, amit csak parciálisan tudok megmagyarázni és magasabb színtű szabvány varázslók segítségét kell még kérnem, hogy pontosan mi is történik, úgyhogy lehet teljes baromság, ami a következő bekezdésben található. |
Mivel a CRTP-nek köszönhetően (a T paraméter a jelenlegi osztályt jelenti, ami örököl az osztály sablonból) a fordító tudja pontosan, hogy a this mutató, hiába visitable_as<…>* típusú, igazából egy T objektumra mutat, így fordítási időben meg tud történni ez a lecastolás.
Emiatt nem szükséges dynamic_cast, hiszen fordítási idejű static_cast is megoldja a problémát.
Így, ha úgy nézzük még mindig van a kódban egy lecast, de ez mégsem dinamikusan történik.
(Az assert lényegtelen igazából, és csak akkor abortál, ha valami nagyon rossz dolog történik, aminek nem lenne lehetséges megtörténnie.)
Igy már egyszerűen csak a típushelyes self mutató tovább tudjuk adni a visit tagfüggvénynek, ami megcsinál mindent amire szükség van.
Sebesség
A dynamic_cast-ot kioperálva a rendszerből jelentős sebességet nyertünk, hogy már kevesebb fölösleges munkát végeztünk.
(Összehasonlító benchmark a cikk végén.)
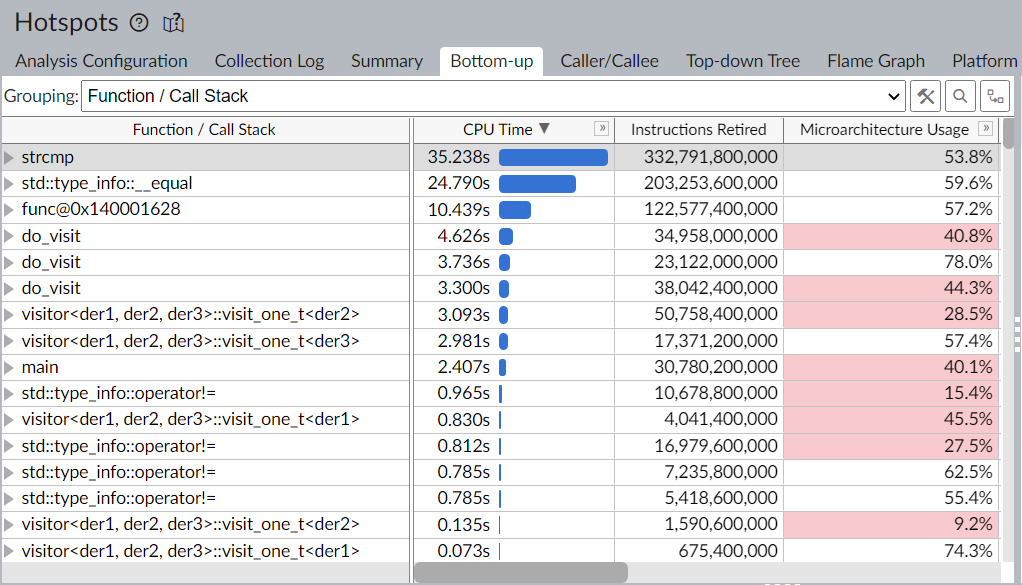
Ezt megvizsgálva azonban azt lehet észrevenni, hogy a szabványos std::type_info osztály GCC implementációja szöveges összehasonlítást végez a típusazonosság megvalósízására.
Látható módon, ez nem optimális, hiszen strcmp dominálja immáron a futásidőnket.
Bár itt már jelentős sebességre tettünk szert, és normális esetben például ez akár egy jó kompromisszum lehetne, hogy ne legyen túl komplikált a kód csak a sebesség miatt; ez egy nagy házi volt. Senki nem fogja a beadás után karbantartani, így teljesen ignorálni lehet a karbantarthatósági szempontot.
Tehát itt az idő egy saját std::type_info-t írni.
Dinamikus látogató, saját típusazonosítókkal
Egyszerű gondolat, hogy kitaláljuk, mit kell tenni jelenleg a sebességért.
Mivel az strcmp alapú megoldás lassú, egyszerűen csak egy olyan verziót kell készíteni, ami nem szövegösszehasonlításon alapul.
Triviális, nemde?
Ehhez szükség van egy olyan osztályra, ami lecseréli az std::type_info-t, illetve egy “operátorra”, ami a typeid szerepét veszi át.
Elsődlegesen az osztály implementáláshoz egy nevezett konstruktor patternt fogunk felhasználni. Ez pusztán azért kell, hogy lehessen normálisan átadni egy explicit típusparamétert a konstruktornak.
Emellet kell még egy statikus számláló, ami mindig a következő értéket tárolja, amit egy típus azonosítására használunk. Ehhez a számlálóhoz készítettünk még egy segéd osztálysablont, egy darab statikus tagfüggvénnyel és egy tagváltozóval.
template<class T>
struct my_type {
static unsigned create_or_get(std::uint_fast32_t& cntr) {
if (_id == 0) _id = cntr++;
return _id;
}
private:
inline static std::uint_fast32_t _id = 0u;
};Mivel a sablonparaméter minden különböző értékére saját típust alkot, így a statikus változó minden különböző T típus esetén külön létezik.
Így képes eltárolni egy adott típus azonosítóját, ha egyszer már inicializálásra került, és inicializálni is tudja, a kapott paraméter használatával.
Ezen osztály köré már felépíthető a saját my_typeid osztályunk.
struct my_typeid {
template<class T>
static my_typeid id_of() {
return my_typeid(my_type<T>::create_or_get(type_cntr));
}
bool operator==(const my_typeid& other) const noexcept {
return other._value == _value;
}
bool operator!=(const my_typeid& other) const noexcept = default;
private:
explicit my_typeid(std::uint_fast32_t val)
: _value(val) { }
std::uint_fast32_t _value;
inline static std::uint_fast32_t type_cntr = 1;
template<class T>
struct my_type {
static std::uint_fast32_t create_or_get(std::uint_fast32_t& cnt) {
if (_id == 0) _id = cnt++;
return _id;
}
private:
inline static std::uint_fast32_t _id = 0;
};
};Minden típusra instanciálódik egy my_type<T> típus, így kap egy saját azonosítót, ezzel pedig tudjuk konstruálni a my_typeid osztályt, ami egyszerűen csak ezt a numerikus azonosítót tartalmazza.
Így az egynelőség/különbözőség operátorok egyértelműen működnek, és egyszerűen egy numerikus egyenenlőség, amit kell csinálniuk.
Ez így már szép és jó, viszont, még egy QoL változtatás, hogy csináljunk egy külön “operátort”, amivel nem kell mindenhol a my_typeid::id_of<T>()-t kiírni.
Ez egyszerűen egy változó sablonnal megoldható:
template<class T>
static auto my_id_of = my_typeid::id_of<T>();Így kész is vagyunk, már csak le kell cserélni minden typeid(T)-t my_id_of<T>-re, és minden std::type_info-t my_typeid-re.
Ez a következő osztályok változtatásával jár:
struct visitor_base {
template<class T>
void visit(T* visited) {
visit_imp(static_cast<void*>(visited), my_id_of<T>);
}
virtual ~visitor_base() = default;
protected:
virtual void
visit_imp(void*, my_typeid) = 0;
};template<class... Ts>
struct visitor : visitor_impl<Ts> ... {
~visitor() override = default;
protected:
template<class T>
[[gnu::always_inline]]
bool visit_one_t(void* typeless_visited, my_typeid tid) {
if (my_id_of<T> != tid) return false;
static_cast<visitor_impl<T>*>(this)->do_visit(static_cast<T*>(typeless_visited));
return true;
}
void
visit_imp(void* typeless_visited, my_typeid tid) final {
(visit_one_t<Ts>(typeless_visited, tid) || ...);
}
};Minden más marad pontosan, ugyan az.
Sebesség
Már jelentősen gyorsabban vagyunk, a teszthez használt ciklus végét meg kellett tízszerezni, az eredeti, eddig használt értékeknél VTune nem tudott mit csinálni a kóddal.
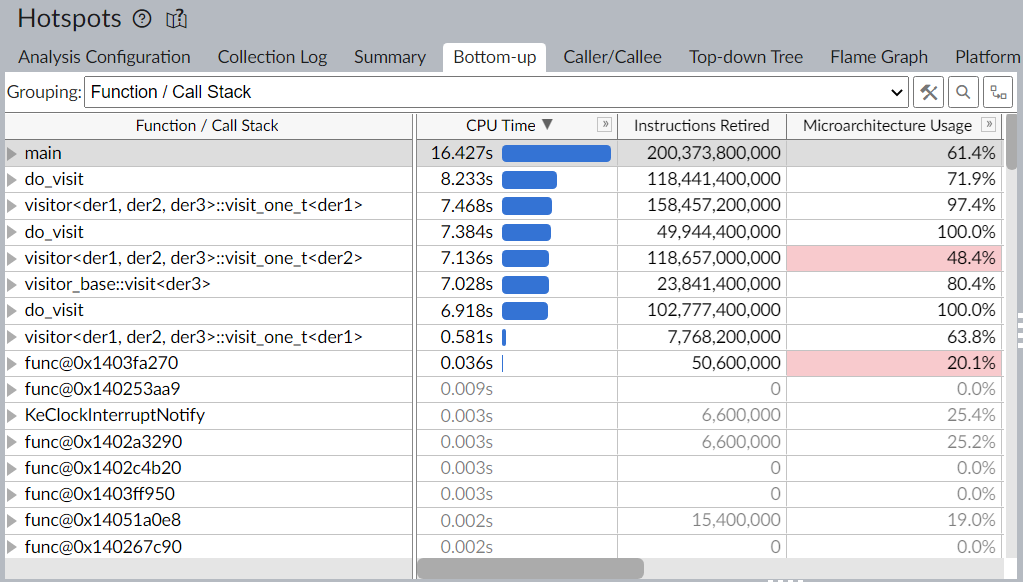
Ebből látható, hogy a kódunk már nem csinál semmi fölöslegeset, és pusztán a feladatát látja el, miszerint látogat.
Összehasonlító benchmarkok
A következőkben az előbb tárgyalt implementációk sebességét vizsgáljuk. Bár három megvalósítást tárgyaltunk, 6 féle került vizsgálatra: minden verzióból kettő, úgy, hogy egyet megpróbáltunk manuálisan elágazásbecsülni.
Az implementációkat következő rövidítésekkel azonosítjuk:
| Név | Dispatch | Típusinformáció | Elágazásbecslés |
|---|---|---|---|
dtb |
|
|
manuálisan branch-predicted |
dtc |
|
|
compiler branch-predicted |
vtb |
virtual dispatch |
|
manuálisan branch-predicted |
vtc |
virtual dispatch |
|
compiler branch-predicted |
vmb |
virtual dispatch |
|
manuálisan branch-predicted |
vmc |
virtual dispatch |
|
compiler branch-predicted |
Ismételt látogatás
Elsődlegesen a legegyértelműbb benchmark, hogy egyre többször hajtjuk végre a látogatás műveletét, ugyanazon az osztályhalmazon. Ehhez egy nagyon egyszerű hierarchiát alkottunk:
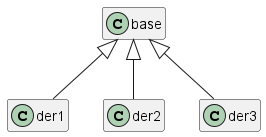
Mind három osztályból konstruáltunk egy darabot, és 100-asával növelve 100 és 1000000 közötti iterációs számmal, sorban meglátogattuk őket.
A használt kód már nincs meg sajnos, viszont alapjaiban a következő, csak rendelkezett időmérést szolgáló std::chrono alapú számlálókkal[2]:
int
main() {
struct nop_visitor final : visitor<der1, der2, der3> {
void
do_visit(der1*) final { ++der1_cnt; }
void
do_visit(der2*) final { ++der2_cnt; }
void
do_visit(der3*) final { ++der3_cnt; }
std::size_t der1_cnt = 0;
std::size_t der2_cnt = 0;
std::size_t der3_cnt = 0;
} nop;
base* d1 = new der1;
base* d2 = new der2;
base* d3 = new der3;
for (std::size_t i = 0; i < std::size_t(@ITERATION_COUNT@); ++i) { (1)
d1->accept(nop);
d2->accept(nop);
d3->accept(nop);
}
delete d1;
delete d2;
delete d3;
std::cout << "der1: " << nop.der1_cnt << "\n";
std::cout << "der2: " << nop.der2_cnt << "\n";
std::cout << "der3: " << nop.der3_cnt << "\n";
}| 1 | Az @ITERATION_COUNT@ érték behelyettesítésével kaptuk meg a különböző benchmarkokat. |
A következő diagramm mutatja a különböző implementációk futásidejét növekvő iterációs szám mellett.
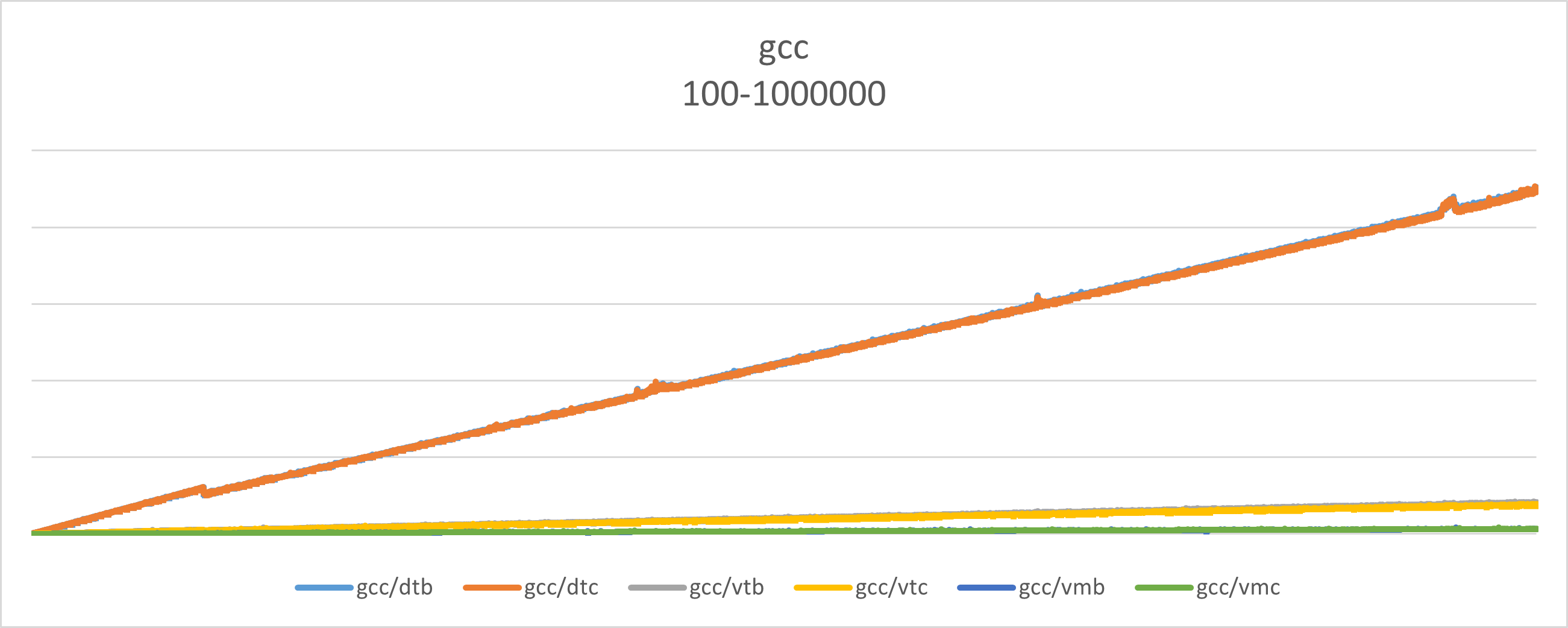
dynamic_cast nélkül
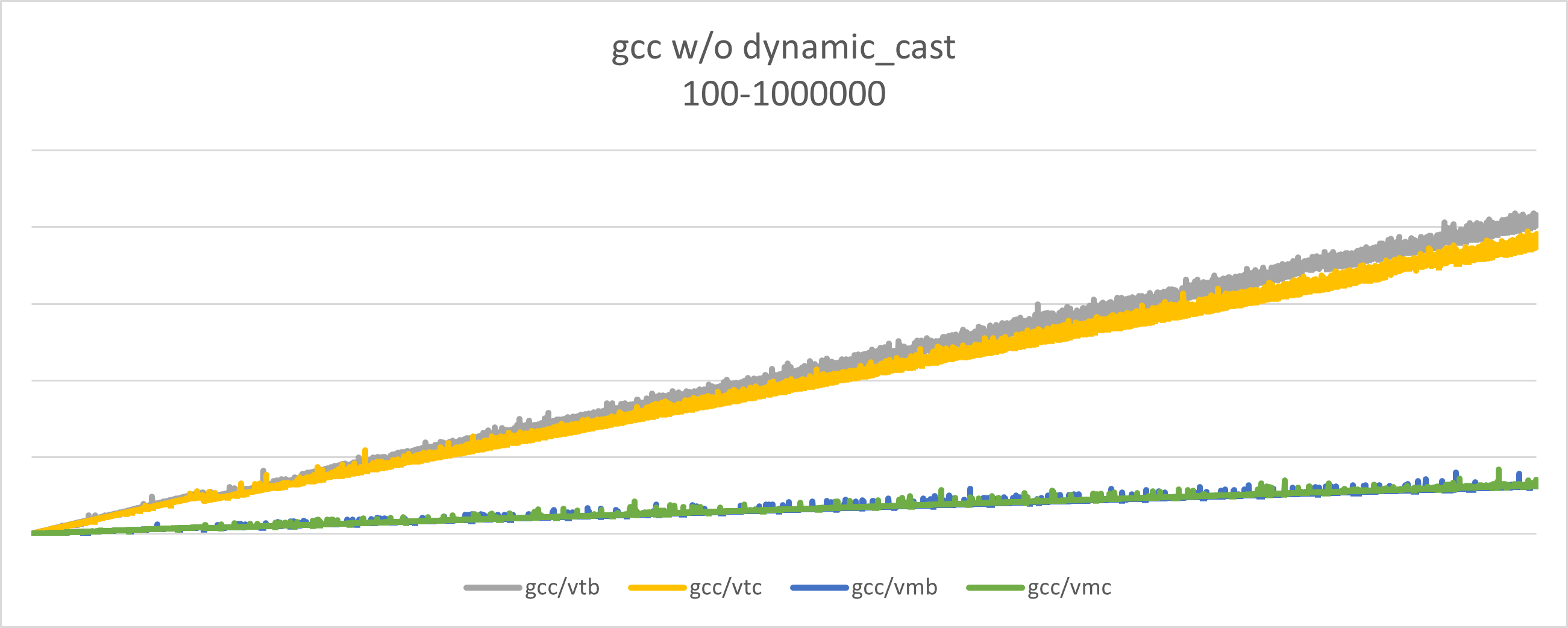
Mivel a dynamic_cast-ot használó implemntáció jelentősen lassabb, mint a másik kettő, így kicsit “összenyomja” a grafikont, hogy a többi adat annyira nem jól látszik.
Ez a grafikon ugyan azokból az adatokból készült, mint az előző, csak a első naív implementáció nem került feltüntetésre.
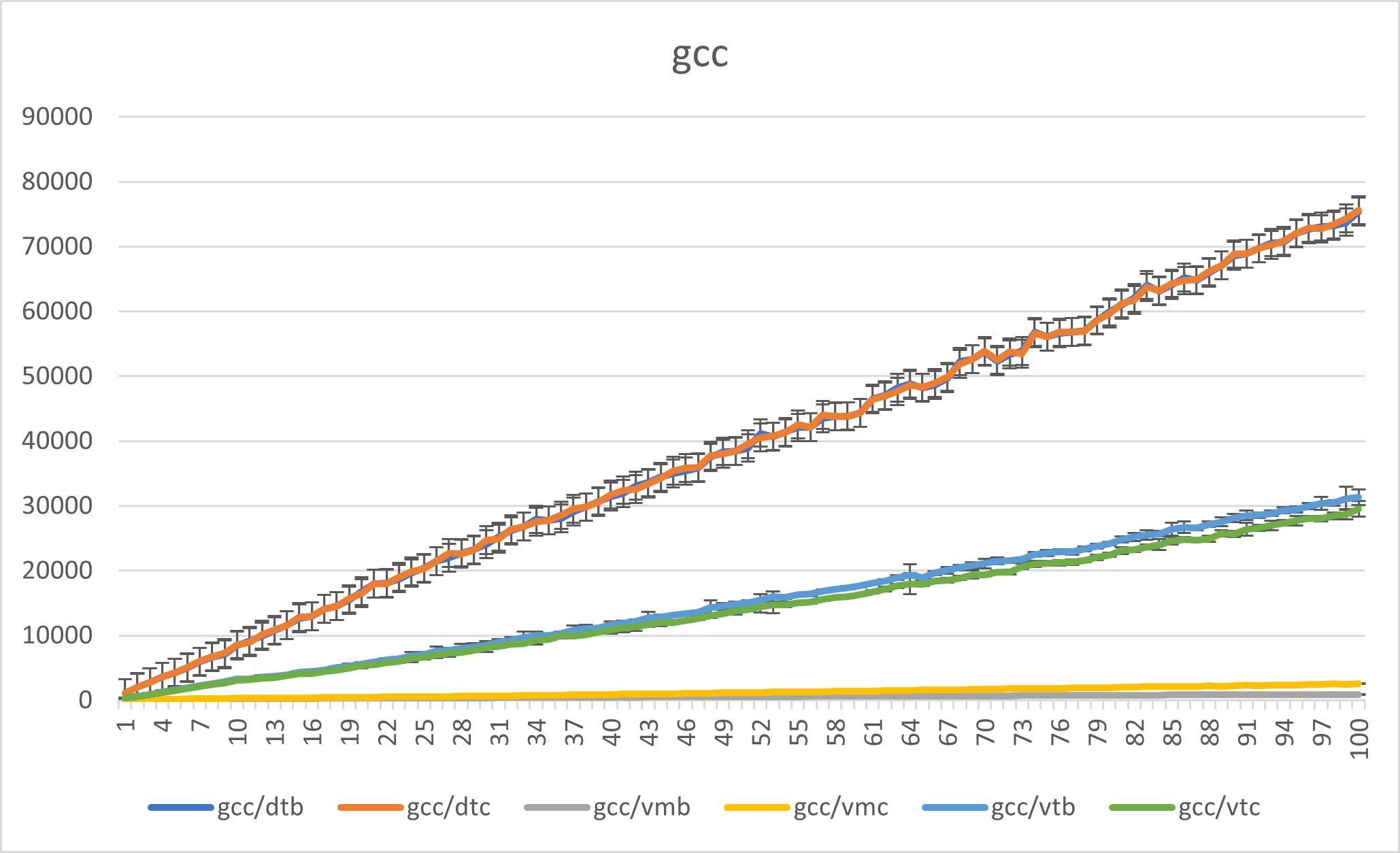
Osztályhalmaz számosság növelés
A második benchmark egyszerűen csak annyit csinál, hogy egy tizesével növekvő osztályhalmazból (10 és 1000 között mérve) random konstruál osztályokat, és azokat végiglátogatja. A vízszintes diagramm tehát most a hierarchiában található osztályok száma.
További varázslási lehetőség
Bár látható módon, jelentős sebesség növekedést értünk el, még esetlegesen dolgot lehetséges lenne megvizsgálni. Jelenleg a vizitálás gyakorlatilag egy lineáris keresést végez az ismert típusok között. Ugye ez jelentősen gyorsabb még így is, mint a másik megoldások, valami trükkösebb implementáció, ami esetlegesen elég osztály esetén átkapcsol valami bináris keresés szerű algorithmusra, még lehetséges gyorsulást érhet el.

Ahogy itt is látszik, a 3 osztályos keresésben, ha elég osztály van, akkor lehetséges, hogy egy bináris keresés, és a vele járó elágazás félrebecslésekkel még gyorsabb, mint a naív lináris keresés.